All applications have to deal with what to do with errors. An unexpected condition is bound to happen one rainy day no matter how good your QA is.
When a problem does happen, would your application display a meaningful message to a user or something to the tune of “A system error occurred. Try again later.”? Are application errors automatically monitored, collected, triaged, and reported to developers?
Handling of Expected and Unexpected Errors in Code
When a runtime error happens inside code it is encapsulated in some sort of an Exception object in languages with structured exception handling. The basic question to ask when handing it is whether the error is by its nature an unexpected error condition or not.
Unexpected error conditions are:
a) problems happening outside of your system control: for example, the network went down, the system password expired, memory ran out, etc.
b) defects in code
In both of these cases code receiving an unexpected error can’t do that much about it. Retry the call? Well, if the called code has a reproducible defect, you’re just going to reproduce it again. Retries might help with temporary outages: e.g. the database went down, but DBAs are busy restarting it right now. However, retries usually have a narrow scope of usefulness and are intrinsically limited: by the number of retires, time interval, user expecting a timely response, etc. Once the limit is reached, the retry logic has to be abandoned and we’re back to handling the original problem.
Error Swallowing Anti-Pattern
I’ve seen this anti-pattern in most projects and languages I dealt with:
// pseudo-code
try {
doSomething(); // this call errors out
} catch (Exception) {
// we're supposed to handle errors, right?
// log some message, perhaps?
// continuing... ?
}
// why do we end up here? the rest of the code might not expect this exceptional condition to have happened
This is what’s known as Error Swallowing. Sweeping under the rug, isn’t it? What happens when an error is “swallowed” could be quite unpredictable. Perhaps, a report rendered ends up with a blank space instead of a piece of data. This situation could lead to bad business decisions and outcomes beyond the immediate system issue.
Error Swallowing is a violation of an important technique in software development: Fail Fast (a.k.a. Fail Early).
Failing fast is a nonintuitive technique: “failing immediately and visibly” sounds like it would make your software more fragile, but it actually makes it more robust. Bugs are easier to find and fix, so fewer go into production.
Jim Shore, September/October 2004 IEEE SOFTWARE
This is an anti-pattern with the shortest fix imaginable: simply not doing this is often good enough of a fix.
// pseudo-code
doSomething(); // this call errors out
// unexpected errors propagate
Advice #1. Let unexpected errors propagate and fail the execution path fast.
Further discussion of the Error Swallowing anti-pattern could be found in Effective Java, 3rd Edition. Item 77: Don’t ignore exceptions.
Expected Errors and Exception Translation
Of course, some exceptional conditions could be expected by system developers. What if a user enters an invalid piece of data? The system ideally should validate all user input. If it really does then a good human-readable message should result. Inside layers of code, which handles expected exceptional conditions, the raised error should be specific to a particular failed condition. In the case of user input failing validation, there are 400 (Bad Request) and 403 (Forbidden) codes in HTTP. A RESTful service on the server side should return them with an error message payload. More generally, you can use e.g. java.lang.IllegalArgumentException in Java or System.ArgumentException in C#.
Should code intercept low-level exceptions and wrap them into higher-level exceptions? This practice is known as Exception Translation. The usefulness of such translation for unexpected exceptions could be limited. So what, if you wrapped DbPasswordExpiredException into ServiceUnavailableError? It would not make difference for an end user. The bottom line is that the system errors out unexpectedly because it broke internally.
Such a translation would make the most sense when you manage to expect a particular problem and display a meaningful message to the user. If you, say, anticipate an error in case a user’s credit card is valid, but over the limit or blocked, you can intercept a particular exception from a lower-level payment provider service, and translate it into a custom error, resulting in “Your credit card was declined. Please update your payment method.“.
Reporting of Unexpected Errors
From a system development perspective, developers should receive as much technical information as possible when unexpected errors happen. This could happen in one of two ways: either from the backend (think, error logs) or from user reports.
All errors could be logged; logs could be monitored and unexpected error reports could be extracted and sent to a developer team’s notification pipeline.
One thing to keep in mind when developing unexpected error notification pipeline is to avoid flooding developers with notifications:
- consider implementing periodic (e.g. nightly) rather than real-time notifications
- consider filtering out repeating errors which are caused by known (filed) defects
Advice #2. Monitor and report unexpected system errors in Production.
When an unexpected inevitably happens what should the user see?
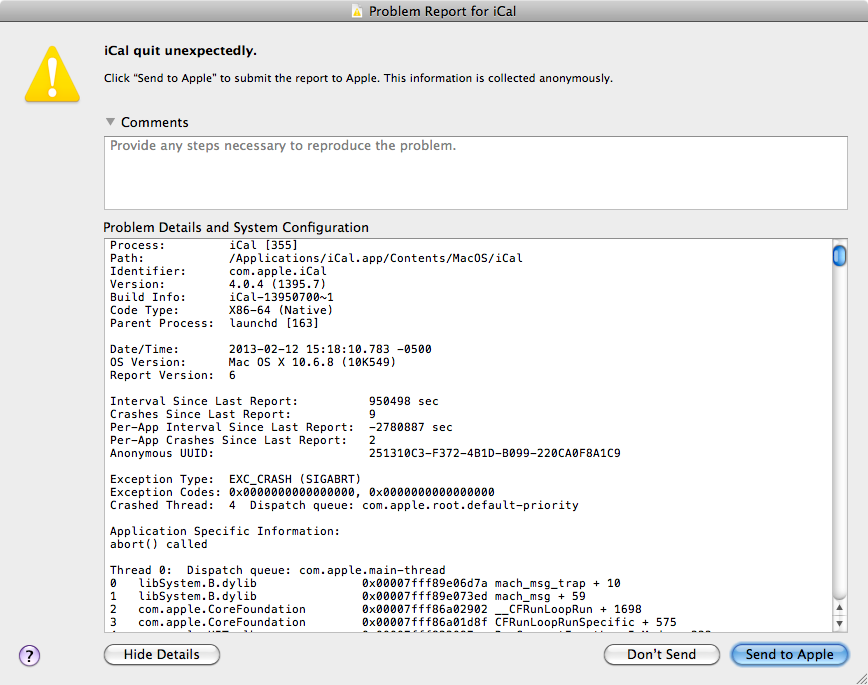
There are security guidelines that warn against showing technical details like this to users on the Internet because bad actors can make the system fail and then get clues out of technical details. This practice of “Error Detail Hiding” is a part of guidelines in the OWASP’s “Improper Error Handling” risk.
Error Detail Hiding though, if followed blindly, might have a large cost. The development feedback loop should better be as short as possible. The development loop is making a change, deploying code to a target environment, and then observing the result. When a system is being developed each error cause needs to be as obvious to developers as possible. While developers can often run the system on their machines (that is, in a Local environment) and just watch the error details in logs the same can’t be said about all other non-production environments.
Non-production environments are not available to end users and tend to be far less exposed to security risks. While security considerations are, obviously, important, each system architecture strikes some balance of functional, User Experience, and other requirements: performance, ease of maintenance, resilience, etc. While trying to strike that balance, keep in mind that Error Detail Hiding is quite detrimental to ease of maintenance and speed of development.
Advice #3. Integrate detailed error reporting into a system and always make technical error details immediately accessible in non-Production environments.
The Improper Error Handling risk used to be in the OWASP Top 10 risks (in 2003-2007) and people, understandably, were reticent to show error details in the apps. The risk is no longer there as of this writing (in the 2021 Top 10 version). It is not hard to guess why: for example, a basic technology stack can be detected without the arduous process of trying to make the system fail. BuiltWith, as of this writing detects 142 technologies used to run amazon.com.
But, what if you still want to minimize the risk? If robust error monitoring/reporting is in place on the backend, then it is fine to hide the details in production because developers would get reports anyway. But if you have nothing like that for your system, then Error Detail Hiding would substantially harm development productivity.
Advice #4. Only hide error details in Production when you have robust system error monitoring (per Advice #2) in place.




You must be logged in to post a comment.